XFinLabs is a leading pioneer of private AI solutions tailored specifically for enterprises.Our proprietary AI platform has been designed from the ground up to improve and enhanceefficiency and insights within any organization by focusing on data integrity, security and quality.

If data security and controlled access are priorities, a private AI enables you to enforce company compliance and oversight procedures. This ensures that only authorized personnel within your organization can access, view, and query the data.

When accuracy is critical, a private AI significantly outperforms public AI models. This is because a private AI's knowledge is exclusively based on the data you provide, minimizing — if not eliminating — the risk of hallucinations. As a result, its responses remain precise, reliable, and founded on facts.

If your data is sensitive, and you don't want it used by a model for training, then a private AI ensures your data stays within your own environment and is used only by your company. Exposing your data to public models oftentimes gives them the option to use it for them own purposes, which is typically not in the best interests of any enterprise.

With a private AI, enterprises can seamlessly access and analyze vast data stores, combining real-time retrieval with deep contextual understanding to generate precise, insightful responses - uncovering hidden patterns, reducing ambiguity, and delivering unparalleled decision-making.
Easily design and deploy AI agents that autonomously retrieve, process and act on information, making more effective for specialized workflows and decision-making.
With an XFinLabs solution, you get direct access to the most popular foundation models from OpenAI ChatGPT and Google Gemini to Anthropic Claude and Xai’s Grok.

Private AI solutions can support autonomous agents that plan, reason, and execute multi-step tasks with minimal human intervention, significantly enhancing productivity.

Unlike public AI, which is often a black box, private AIs allow companies to fine-tune models with proprietary data, ensuring domain-specific accuracy and alignment with business needs.

With a private AI companies are able to create tailored personas with specific knowledge, tone, and behavior, enabling more personalized and context-aware interactions.
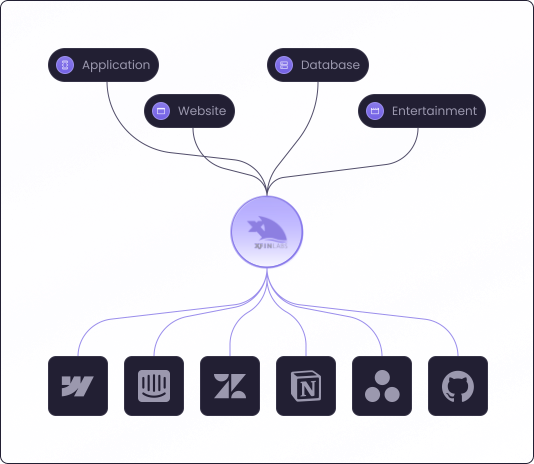
Central to the XFinLabs platform is the concept of Reports. Each report represents its own private AI database, complete with its own personas, models and logic. Reports can contain a single file or multiple files, each designed to tackle a specific task or analysis.

XFinLabs supports the most popular foundational models. This gives people the flexibility to control how your model, thinks, acts and responds to questions. For example, some companies might prefer to use Google’s Gemini for a report, and for a specific section in that report switch to OpenAI's ChatGPT or Anthropic's Claude. You can opt for succinct responses or long form paragraphs, visual charts and dashboards or tables and text.

The true power and versatility of XFinLabs is that it can take all your company data and make that accessible for an AI model. This data can be files or internal databases that connect natively to XFinLabs. You can even scrape the web for external information to further enhance any responses or bring in real-time updates.
People want to leverage the power of AI to help them become more productive and to reduce time consuming and repetitive task. This frees them up to focus on what they do best - analyzing and understanding data. XFinLabs does the heavy lifting, generating reports that accurately and concisely respond to what the employee needs. Since the data is internal, employees can feel confident that what they get is exactly what they put in, no hallucinations, no stories - just their data their way.
A private AI is an AI system hosted within a company’s own network and infrastructure. While companies can upload a file to a public AI system, such as ChatGPT, there are limitations on how much data you can provide, along with context. (This is especially the case since the model has not been trained on an organization’s private and/or proprietary data.) As such people run a higher risk of the public AI model hallucinating (making stuff up). This is a major barrier for enterprise adoption. A private AI solves this problem by preparing the data before it is passed to the AI model for analysis. This is done by storing data (files, databases, web sites etc.) into a special multi-dimensional database called a vector database. When a user asks a question, the vector database retrieves and encrypts only the most relevant information before passing that to the model of choice. This approach means that the AI model only sees necessary context and not the company's entire data before it generates a response. (A technique referred to as retrieval-augmented generation or RAG.) If your company is looking to leverage AI, and security and privacy is an issue, then a private AI database and implementation is a great choice. Sensitive information is protected while your users get to benefit from the power and productivity enhancements inherent to AI.
When discussing how AI systems communicate, everything starts and ends with the Large Language Model (LLM). In short, the LLM is the language processing center of artificial intelligence. There are many types of LLMs, including OpenAI’s GPT, Meta’s LLaMa, and Google’s Gemini. Each operates slightly differently and is trained on different datasets. However, they are all designed to understand language and generate responses that mimic how people talk, write and in some cases, create. Bascailly the LLMs primary job is to understand your question then determine the best response based on the context of the question and data it has access to. For example, if you asked about a ”club”, it would understand whether you meant a golf club, the club house or even a club sandwich.
In a retrieval-augmented generation (RAG) system like XFinLabs, prompt engineering is the practice of guiding an AI model to think and respond in ways that align with an enterprise's specific needs. This is especially vital for private AI models, which—by design—do not have access to the vast, diverse datasets used to train public models. As a result, private AIs require well-structured, precise prompts to generate accurate, relevant, and context-aware responses. Without thoughtful prompt engineering, outputs may lack the depth or specificity typically seen in public models. To address this, the XFinLabs platform offers a robust and highly customizable prompt engineering workflow, providing clients with the tools necessary to fully harness the capabilities of their private AI systems.
No. However, they do work together. RAG systems need an LLM, like ChatGPT, to be able to ask questions and get an answer. In this scenario, RAG is responsible for categorizing and storing data, while ChatGPT is responsible for generating a response to the data.
This is a good question and can be answered by what you want to do. For example, if you want to use AI with your own data, or pull data in real-time from external sources, then you'll want a private AI. Why? Because the data you want to query has not been seen before by the public LLM. Remember, LLMs are trained on freely available data. If you have data that has never left your building, the LLM will not be able to adequately answer your question. This is where private AI systems offer the best solution for security and privacy. If you want to do market research, craft an email or write a book, then using a public AI solution is perfect.
XFinLabs Studio is the technology that drives XFinLabs' private AI system. It does all the heavy lifting behind the scenes, from building private AI databases, fine-tuning models, developing effective prompts, and enabling the XFinLabs proprietary Agentic AI. Agentic AI represents the next level of AI assistants - ones that can handle complex tasks and autonomously adjust there approach based on what they discover. This makes Agentic AI an essential tool for companies working with large, disparate data from both private and public sources, especially when they need to create detailed and comprehensive reports such as financial analyses or legal documents.
Yes, private AIs are an amazing innovation of AI, especially when it comes to working with private data. However, there are some downsides to consider. The most obvious is GIGO - garbage in, garbage out. Because there is not a lot of data to learn from, anyone uploading garbage is going to have an outside impact on the quality of the results. Secondly, there are performance issues - if you are working on large datasets, it may take longer to create the database to store this data, and retrieval may also be not as fast as public systems. Finally, bias. There are plenty of examples of how bias has affected the results of some public AI systems. Bias can often be amplified within a company and care should be taken when creating prompts. The bottom line... AI is a powerful tool that needs to be respected and treated accordingly. Organizations need to spend time and be careful about how they tune their AI models and the types of data and access they allow. When used to handle specific tasks, there is no better way to enhance business productivity and insight. If no specific task comes to mind, stick with ChatGPT or any other of the amazing publicly available AI systems.